
Scaling CMR Uploads in AIMC-IC: Lessons from 100k Line Items
Part I: Introduction
In military logistics, the Consolidated Memorandum Receipt (CMR) is not simply an administrative document. It is the authoritative inventory record that ties equipment to a Subordinate Unit Code (SUC), and it forms the backbone of accountability during FSMAO inspections.
AIMS Inventory Control (AIMS-IC), part of Troika Solutions’ Asset Information Management Solutions (AIMS) suite, is designed to automate the processes surrounding CMR data. However, until recently, the ingestion and processing pipeline for CMR uploads suffered from fragility at scale. Files with more than a few thousand line items triggered race conditions, produced duplicate Record Jackets, and sometimes left Items or Client Settings uncreated
Given that a single CMR may contain upwards of 15,000 line items, and inspection schedules under MARADMIN 399/25 demand complete accuracy, this fragility was unacceptable. The AIMS-IC team committed to re-engineering the upload path to be idempotent, concurrency-safe, and performant. While the user-facing system has seen dozens of small refinements, this article focuses on one critical under-the-hood rebuild: the orchestration of CMR uploads.
Part II: The Orchestration Challenge
When we first implemented the CMR upload pipeline in AIMS-IC, the design philosophy was straightforward: move the file through a sequence of stages, each handing control to the next. The goal was simplicity — ingest the file, archive old data, process new line items, and build out dependent objects such as Items, Record Jackets, Inventories, and Client Settings.

Original Process
The early implementation followed a linear, stage-to-stage model:
Capture the uploaded CMR and archive existing Record Jackets.
Split the file into batches and create line items.
Identify line items without corresponding Items and create them.
Unarchive existing Record Jackets that matched the upload.
Create new Record Jackets for remaining line items.
Generate Inventories where required.
Create Client Settings if none existed.
On paper, this appeared workable. Each stage advanced immediately once its predecessor finished. In practice, however, the system exposed significant weaknesses when tested against large files.
Where the linear approach failed
Sequential bottlenecks: Each line item was processed one-by-one, with enforced one-second intervals between operations. For a 10,000-line CMR, this meant hours of processing per stage, multiplied across multiple stages. Uploads that should have taken minutes extended into overnight jobs.
Concurrency gaps: Stages did not run in isolation. A downstream stage (e.g., creating Record Jackets) could begin while an upstream stage (e.g., creating Items) was still committing changes. This created orphaned records and unpredictable results.
Race conditions: Without centralized control, multiple branches of the workflow could evaluate conditions simultaneously. Two processes might both conclude that a Record Jacket was missing and attempt to create it, leading to duplicates.
Inefficient list operations: The design relied heavily on a single step to “make changes to a list of things” and client-side searches. For example, unarchiving Record Jackets required scanning entire lists and cross-matching instance numbers, each step triggering new queries. At scale, these nested searches became prohibitively slow.
Lack of authoritative stage control: Each stage decided for itself whether to advance. If one stage failed silently, subsequent stages might still trigger, leaving the pipeline in a half-complete, inconsistent state.
The shift to Master Orchestration
After repeated failures in scale testing, we recognized the need for a central coordinator. Instead of chaining stages together directly, we introduced a Master Orchestrator that alone governs progression.
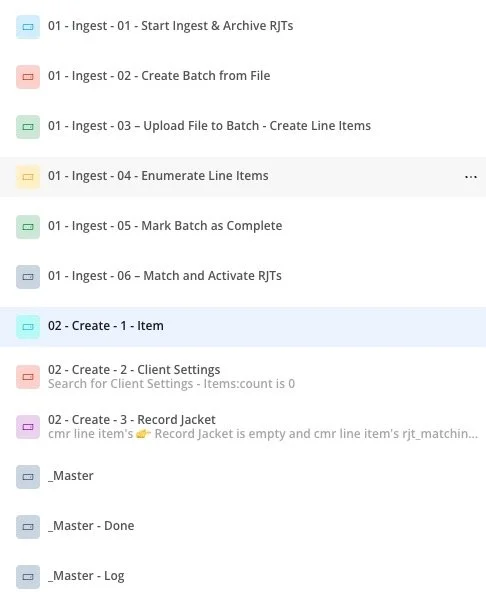
New Process
In the new design:
Each stage reports its results back to Master.
Master performs count-vs-count verification (e.g., “Are all required Items present?”) before advancing.
Lock flags prevent concurrent processes from double-creating the same record.
Stages only progress when upstream dependencies are fully satisfied.
Part III: Engineering for Scale
The introduction of a Master orchestrator solved the high-level problem of moving a CMR upload through its lifecycle. But orchestration alone was not enough. To support CMRs with tens of thousands of line items, we needed to engineer for scale. That meant eliminating fragile logic, ensuring concurrency safety, and making progression through each stage deterministic and auditable.
During load testing, the weak points became clear: duplicate creation, race conditions, and premature state advancement. Each issue was addressed with targeted technical changes, from low-level query mechanics to architectural conventions. What follows are the key principles and the actual mechanics that transformed CMR upload from fragile to bulletproof.
Part III: Section A — Data Integrity

The first step toward making CMR upload bulletproof was ensuring that every record created by the pipeline was correct, unique, and deterministic. Early iterations of AIMS-IC handled data checks in the application layer using a :filtered operator. This worked for small uploads but failed as soon as we pushed into the tens of thousands of line items. To engineer for scale, we had to push correctness down into the database itself.
1. From Filters to Database Constraints
Original approach (fragile at scale):
Search for Items:filtered (TAMCN = X, NSN = Y, Name = Z):count
We fetched all Items first, then applied the filter in memory.
At 10k+ line items, this meant thousands of unnecessary rows were loaded.
Worst of all, two asynchronous processes could both evaluate “count = 0” and proceed to create duplicates.
Rebuilt approach (DB-level guard):
Search for Items
where TAMCN = this TAMCN
and NSN = this NSN
and Name = this Name
:count = 0
Now the database enforces uniqueness directly. No excess rows, no wasted compute, and—critically—no race where two jobs “both see zero.” If the record exists, the DB will always return it.
2. Canonical Deduplication Keys
We next defined canonical keys for every entity in the model. This ensured that uniqueness was unambiguous and enforced consistently across the orchestration.
Items:
(TAMCN | NSN | Name)Client Settings – Item:
(Client, Item)Record Jackets:
(Client, Item, Instance Number)
With these keys in place, every create action can be guarded by a deterministic DB query:
Only when
Search for Record Jackets
where Client = this Client
and Item = this Item
and Instance Number = this Instance
:count = 0If the entity already exists, the pipeline skips creation. This single rule eliminated entire classes of duplication bugs.
3. Idempotency at Multiple Layers
The system had to be idempotent—safe to re-run the same upload without creating duplicates. We enforced uniqueness checks not just at the Item level, but at every dependent layer:
Items: guard on
(TAMCN | NSN | Name)Client Settings: guard on
(Client, Item)Record Jackets: guard on
(Client, Item, Instance Number)Inventories: guard on
(Record Jacket)
This multi-layer protection means the pipeline can recover from partial failures or retries without corrupting data. If a stage runs twice, the second run becomes a no-op.
4. Stage Advancement via Count-vs-Count Verification
Finally, we hardened progression logic by replacing “flip a flag” transitions with count-vs-count verification. For example, Master only advances past Client Settings when the database shows all expected settings are present:
Only when
Search for Client Settings
where Item is in (CMR Line Items’ unique Items)
and Client = this CMR’s Client
:count = (CMR Line Items’ unique Items:count)
If even one Client Setting is missing, the handler stage does not advance. This prevents the pipeline from drifting into a “half-complete” state.
5. Stateless Stage Validation
One of the most subtle but impactful changes was eliminating reliance on the outputs of previous stages or the current value of the Master handler’s state. In the original design, later stages often consumed the “results” of prior steps (e.g., “Items just created in Step 2”) or trusted the Master’s stage flag as evidence that prerequisites were complete. This worked at small scale but broke down under concurrency and partial failures.
The problem:
If a stage failed silently, downstream logic would still accept its partial output and continue.
If two asynchronous processes were mid-write, the “handed-down” result might not represent the real state of the database.
The Master’s stage value only told us what should have happened, not whether the database reflected it.
The solution was to make every stage self-validating and stateless. Instead of relying on inherited lists or stage flags, each step now recalculates its own conditions directly against the database:
Example: Client Settings validation
Search for Client Settings
where Item ∈ (CMR Line Items’ unique Items)
and Client = this CMR’s Client
:count = Line Items’ unique Items:count
If the database shows the expected counts, the stage advances. If not, the stage halts or retries. No assumptions, no dependencies on in-memory results, and no blind trust in the Master’s status flag.
This stateless validation ensures that:
Every stage reflects the ground truth of the database.
Partial failures cannot silently cascade.
Re-runs are safe because each step checks completeness directly.
By enforcing this discipline, we removed an entire class of “false positive” progression bugs — where the pipeline looked like it had advanced, but the underlying records were missing or inconsistent.
Part III: Section B — Concurrency Control

Once the database was hardened against duplicates, the next challenge was concurrency. With thousands of asynchronous API calls executing in parallel, the orchestration needed guarantees that no two processes could “step on each other.” The problems we faced included race conditions, double-fires, and premature state advancement.
This section describes the techniques we introduced to enforce deterministic behavior under load.
6. Lock Flags for Record Jackets
Even with database-level uniqueness, asynchronous jobs could still collide. Consider two workflows evaluating the same line item:
Both check whether a Record Jacket exists.
Both see “none found.”
Both attempt creation.
To prevent this, each CMR Line Item carries a Boolean lock flag: rjt_in_progress.
Workflow logic:
If LineItem.rjt_in_progress = no:
→ Make changes to LineItem.rjt_in_progress = yes
→ Schedule API → Create Record Jacket
Else:
→ Skip
The first process to touch the line item sets the flag, locking it. Subsequent processes immediately skip. This eliminated duplicate jacket creation even under heavy parallelism.
7. Reverse-Ordered State Changes
Originally, the pipeline advanced the CMR Handler Stage too early. For example, the stage might move from Create Items to Create Record Jackets while some Item jobs were still running. The result: Record Jacket creation jobs firing against missing Items.
The solution was reverse-ordered state changes:
Run Item creation jobs.
Run Client Setting jobs.
Run Record Jacket (and Inventory) jobs.
Only after success → Advance CMR Handler Stage.
This ordering guarantees that downstream jobs never start until all upstream dependencies are complete. The handler stage now reflects reality, not aspiration.
8. Master Orchestrator as the Single Gatekeeper
In the original design, stages called each other directly. Create Items might schedule Create Client Settings; Create Client Settings might schedule Record Jackets. This distributed control led to unpredictable overlap and retries.
The updated design consolidates control in a Master Orchestrator. Each stage reports its work back to Master, and only Master decides whether to advance.
This eliminated “phantom runs” where multiple paths triggered the same stage. The orchestration now follows a disciplined flow: Master checks → Stage executes → Master re-checks.
Part III: Section C — Scaling Strategy

With correctness and concurrency under control, the final challenge was scale. Marines routinely deal with CMRs containing tens of thousands of line items. A fragile orchestration that works at 500 lines but collapses at 50,000 is unacceptable. We needed a pipeline that could reliably process 100,000+ rows in under an hour, without throttling, and without sacrificing determinism.
9. Batch Processing at Fixed Size
Processing every line item in one monolithic job is impractical. Failures are harder to recover from, and our API engine is not designed for single calls over massive datasets.
We chose a fixed batch size of 100 line items. This value represents the sweet spot:
Large enough to minimize orchestration overhead (fewer API calls).
Small enough to isolate errors (one batch fails, not the entire upload).
Predictable — Marines and inspectors can expect consistent behavior regardless of file size.
Workflow logic:
Split CMR CSV → batches of 100 rows
For each batch:
Schedule API → Create Line Items
Schedule API → Create Client Settings
Schedule API → Create Record Jackets
This batching strategy gave us both throughput and fault isolation.
10. No-Throttle Asynchronous Scheduling
Some systems slow down intentionally under load. We made the opposite decision: run everything asynchronously, without artificial throttling.
Each batch runs in parallel.
Each API workflow executes independently.
Dependencies are enforced only by Master, not by artificial delays.
This design choice is why the system can process 100k+ line items in less than one hour. Marines don’t wait for serialized processing — they benefit from parallel execution controlled by strong idempotency rules.
11. Deterministic Indexing with UID + Created Date
Deterministic ordering of line items was essential for logging, reconciliation, and ensuring that every row in a CMR could be traced end-to-end. Our stack does not expose a native :index operator, and so relying on :items until This Line Item:count was fragile — especially when multiple rows were created at the same millisecond. In those cases, ordering became non-deterministic, and some items risked being skipped.
To solve this, we introduced a unique identifier (UID) for every line item at creation time. We then sorted line items using a compound key:
Sort order = Created Date + UIDThis guarantees stable ordering, even when timestamps collide. Every line item now has:
A deterministic position in its batch.
A traceable identity tied to logs and downstream Record Jackets.
Resilience against concurrency artifacts caused by parallel creation.
With this safeguard, Marines and auditors can rely on consistent indexing whether a CMR contains 11 rows or 100,000.
12. Stage Advancement via Count-vs-Count Checks
We deliberately avoided “trusting flags.” Instead, Master advances stages only when database counts align.
Example: Client Settings verification.
Only when
Search for Client Settings
where Item ∈ (Line Items’ unique Items)
and Client = this CMR’s Client
:count
= Line Items’ unique Items:count
If even one Client Setting is missing, Record Jacket creation does not begin. This guarantees completeness before progression, even at scale.
Part III: Section D — Resilience & Auditability

A pipeline that “works most of the time” is not good enough for Marines preparing for FSMAO inspections. They need confidence, evidence, and a clear audit trail. This section details how we built resilience into the workflow and made its behavior transparent at every stage.
13. Structured Logging and Improved Semantics
Logs are not an afterthought — they are the operational truth. We introduced CMR Log Events as first-class records. Each log entry captures:
Stage (e.g.,
create_items,create_client_settings).Action (Ran, Skipped, Condition Failed).
Details (“Processed 11 Items,” “Created 4 Client Settings”).
Correlation ID linking logs to a specific CMR upload.
Example log flow for one CMR:
🪵 Log - Create Items → Processed 11 Items
🪵 Log - Create Client Settings → Created 4 Settings
🪵 Log - Create Record Jackets → Processed 18 Jackets
We also standardized semantics:
“Action condition failed” → The query guard prevented execution.
“Skipped” → Stage not needed (e.g., no new Items).
“Processed X” → Stage completed successfully.
This makes logs legible to both Marines and auditors.
14. Per-Stage “Skip If Not Needed” Guards
Before, every stage ran even if there was nothing to do. Now, each step evaluates its relevance:
Only when
Search for New Items :count > 0
→ Run Create Items
Else
→ Log “Skipped Create Items”
This prevents wasted compute and produces cleaner logs. Auditors can see at a glance why certain steps did not execute.
15. Archival and Unarchive Logic for Record Jackets
One of the trickiest problems was reconciling old data with new uploads. CMRs are living documents — a new upload may add, remove, or change equipment.
Our solution:
Archive all Record Jackets in the SUC at the start of the upload.
Unarchive jackets with instance numbers present in the new CMR.
Create new jackets for all remaining instances in the upload.
This ensures:
No stale jackets linger.
No manual cleanup is required.
GCSS-MC remains the single source of truth.
If it’s in GCSS, it stays live. If it’s missing, it gets archived.
16. Inventory Auto-Creation
Previously, Marines had to manually initialize an Inventory for each Record Jacket. That is no longer necessary.
Now, every Record Jacket automatically spawns its Inventory at creation time.
When Record Jacket created:
→ Create new Inventory (linked 1-to-1)
This guarantees readiness for inspections. Marines no longer have to remember a manual step; the system enforces it.
17. Correlation of Line Items to Created Objects
Each CMR Line Item now directly references its Record Jacket. This creates a chain of traceability:
CSV Row → Line Item → Record Jacket → Inventory
During an FSMAO inspection, this traceability is invaluable. Auditors can walk from the raw upload file to the corresponding jacket and inventory without ambiguity.
18. Idempotency at Multiple Layers
Finally, we enforced idempotency not just once, but everywhere:
Items — One per (TAMCN | NSN | Name).
Client Settings — One per (Client, Item).
Record Jackets — One per (Client, Item, Instance Number).
Inventories — One per Record Jacket.
Each layer can be safely retried. If a batch fails mid-stream, re-running it will not duplicate data. This “retry without fear” principle is essential in large-scale asynchronous systems.
Part IV: Mission Impact
Engineering a bulletproof CMR upload pipeline is not an academic exercise. The reason we invested dozens of hours rebuilding orchestration was to solve tangible problems Marines face in the field and to align with the compliance environment Marines now operate in.
1. From Fragile to Deterministic
Before: Uploading a CMR was fragile. Large files could stall. Missing Items left gaps in accountability. Duplicate Record Jackets introduced noise and confusion. Marines often had to re-run uploads or manually reconcile results — a process that consumed time and undermined trust in the system.
Now: Uploading a CMR is deterministic. Every line item is processed, and every dependent object — Item, Client Setting, Record Jacket, and Inventory — is created exactly once. Older jackets no longer present in GCSS-MC are archived automatically. Marines no longer troubleshoot mismatched counts; they upload once, and the system guarantees correctness.
This shift is not cosmetic. Errors in equipment accountability are more than paperwork issues — they cascade into readiness reports and unit effectiveness. By enforcing idempotency and race-condition safeguards, AIMS-IC ensures:
No duplicate Items inflate counts.
No missing Client Settings create blind spots in inventory cycles.
No stray Record Jackets persist once GCSS-MC has dropped them.
The effect is that readiness data in AIMS-IC now mirrors the Marine Corps’ system of record with both speed and precision.
2. Time Savings During FSMAO Inspections
Field Supply and Maintenance Analysis Office (FSMAO) inspections are high-pressure events. Inspectors must validate that Subordinate Units of Control (SUCs) maintain accurate accountability of equipment.
Impact of the new pipeline:
A CMR can now be uploaded and reconciled at scale (100k+ line items in under an hour).
Record Jackets are automatically created or archived to match the authoritative source of record: GCSS-MC.
Client Settings ensure that each SUC’s unique inventory method (batch vs serial) and frequency is respected.
For Marines under inspection, this means they spend less time explaining discrepancies and more time demonstrating compliance.
3. Compliance with MARADMIN 399/25
On August 28, 2025, MARADMIN 399/25 published the FY26 FSMAO inspection schedule. Units across the Marine Corps now face a known calendar of compliance checkpoints.
With the new CMR upload pipeline, AIMS-IC is ready to support those inspections directly:
Units can reconcile their jackets against GCSS-MC immediately upon receiving an updated CMR.
FSMAO inspectors can rely on AIMS-IC as the local system of truth, knowing it reflects the exact structure of the uploaded CMR file.
The system eliminates the need for Marines to manually intervene in data alignment, reducing inspection stress and error rates.
4. Integration with Marine Workflows
The user experience for Marines is simple by design:
Download CSV from GCSS-MC.
Upload CMR into AIMS-IC.
The system ingests, creates Items, applies Client Settings, generates Record Jackets, and produces associated Inventories.
Legacy jackets are archived automatically if they no longer appear in the authoritative file.
What Marines see is a clean dashboard reflecting their equipment posture. What happens behind the scenes is the result of a hardened orchestration engine that was stress-tested, rebuilt, and proven to scale.
Part V: Closing Reflections
Engineering the new CMR upload pipeline was not about adding features for the sake of features. It was about addressing a core fragility in how Marines interact with their systems of accountability. When a single upload can involve tens of thousands of line items, the orchestration behind the scenes must be uncompromising.
This was not a minor patch. It required rebuilding the entire ingestion process — replacing step-to-step chains with a master orchestrator, introducing lock flags to prevent race conditions, restructuring queries to operate on database constraints rather than advanced filters, and enforcing idempotency at every level. Each of these changes demanded careful testing, iteration, and validation under realistic loads.
The result is a pipeline that feels simple to the Marine: upload a file, and it works. But beneath that simplicity lies a carefully engineered system that can process 100,000+ line items in under an hour, without duplicating Items, misapplying Client Settings, or creating orphaned Record Jackets. Older jackets are automatically archived when they no longer exist in GCSS-MC, ensuring the local data always reflects the source of record.
This work reflects our philosophy at Troika Solutions: invest the time where it matters, engineer for correctness under pressure, and deliver tools that Marines can depend on when inspections, readiness reports, and operations demand it.
The CMR upload is now bulletproof. It is faster, more reliable, and aligned with the FY26 FSMAO inspection schedule published under MARADMIN 399/25. Most importantly, it removes fragility from Marine workflows, ensuring accountability is never in doubt and letting units focus fully on mission execution.